
Model-based RL
一、Model-based RL
基础算法
模型基强化学习(Model-Based RL)的基本流程如下:
对于每一次迭代 (iter = 1, 2, ...): 1. 在当前策略下收集数据。 2. 使用过去的数据学习一个动态模型。 3. 利用这个动态模型来改进策略。 * 可以通过在学习到的模型上进行时间反向传播(backprop-through-time)来优化策略。 * 也可以将学习到的模型作为一个模拟器来运行其他强化学习算法。
为什么使用Model-Based RL?
- 数据效率:从数据中学习模型,可能比单纯的策略梯度更新带来更显著的策略提升。
- 可重用性:学习到的模型如果足够通用,可以被复用于其他任务。
为什么不一直使用Model-Based RL?
尽管它有很高的样本效率(sample efficiency),但也存在一些问题:
- 训练不稳定性
- 无法达到与无模型(model-free)方法相同的渐进性能
Model-based RL中的过拟合问题
- 标准过拟合 (监督学习中)
- 神经网络在训练数据上表现良好,但在测试数据上表现不佳。例如,在根据(s, a)预测s_next时。
- Model-based RL中的新挑战
- 策略优化倾向于利用那些没有足够数据来训练模型的区域,这会导致灾难性的失败。
- 这个问题被称为“模型偏差”(model-bias)。
二、Robust Model-based RL:Model-Ensemble TRPO (ME-TRPO)
ME-TRPO(模型集成信赖域策略优化)被提出来解决“模型偏差”问题。
Vanilla Model-Based Deep RL 算法
这是ME-TRPO的基础对比算法。
- 初始化策略
和模型 。 - 初始化一个空的数据集D。
- 循环直到策略在真实环境中表现良好:
- 使用策略
从真实环境f中收集样本并添加到D中。 - 循环直到性能停止提升:
- 使用数据集D训练模型
。 - 使用策略
从模型 中收集虚拟样本。 - 在虚拟样本上使用BPTT(Backpropagation Through Time)更新策略。
- 评估性能
。
- 使用数据集D训练模型
- 使用策略
ME-TRPO 算法
- 初始化策略
和所有模型 。 - 初始化一个空的数据集D。
- 循环直到策略在真实环境中表现良好:
- 使用策略从真实系统中收集样本并添加到D中。
- 使用数据集D训练所有模型。
- 循环直到性能停止提升:
- 使用策略
从模型集合 中收集虚拟样本。 - 在虚拟样本上使用TRPO更新策略。(核心区别:使用所有模型进行优化)
- 评估每个模型下的性能
for , ..., Κ。
- 使用策略
ME-TRPO 评估
实验环境: 
与SOTA(State of the art)方法的比较:
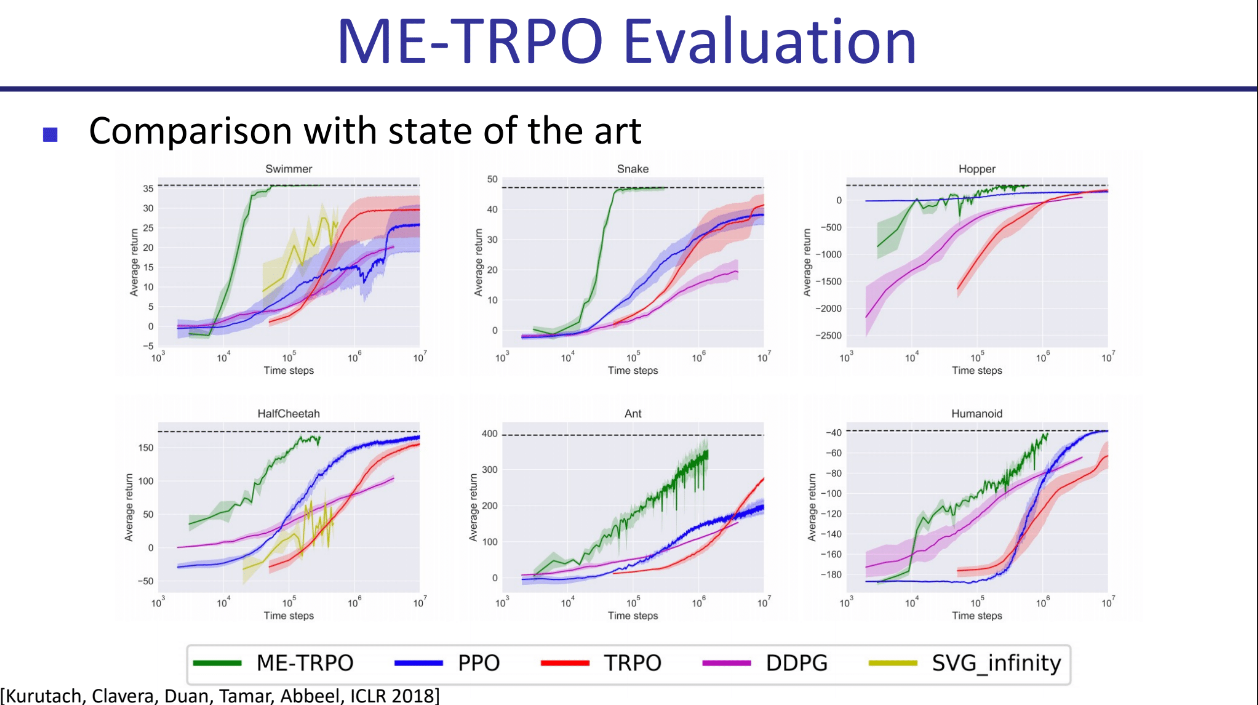
ME-TRPO在多个环境(Swimmer, Hopper, HalfCheetah, Ant, Humanoid, Snake)中与PPO, TRPO, DDPG等先进的无模型方法进行了比较。结果显示,ME-TRPO在样本效率上具有显著优势,能用更少的样本达到甚至超越其他方法的性能。
ME-TRPO 消融实验
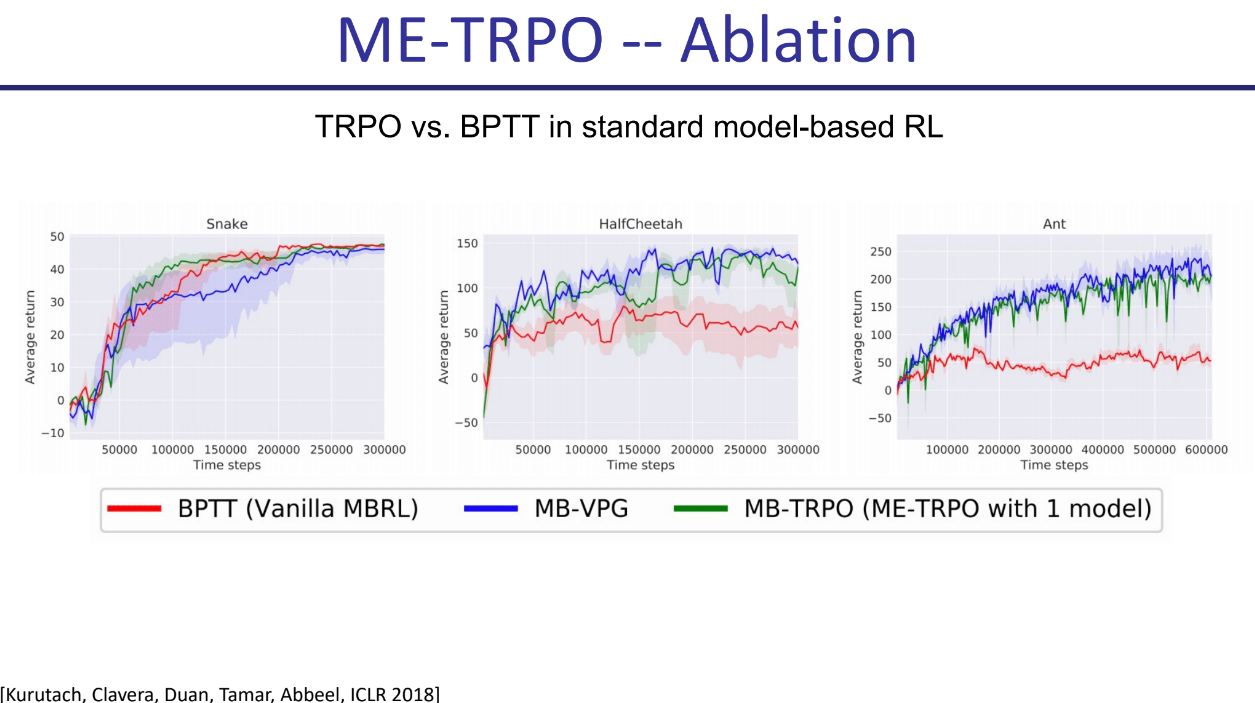
TRPO vs. BPTT 在标准Model-based RL中的比较

- 实验对比了在单个模型下,使用TRPO更新策略(MB-TRPO)与使用BPTT更新策略(Vanilla MBRL)的效果。结果显示,在Snake, HalfCheetah, Ant环境中,基于TRPO的更新方式性能更优且更稳定。
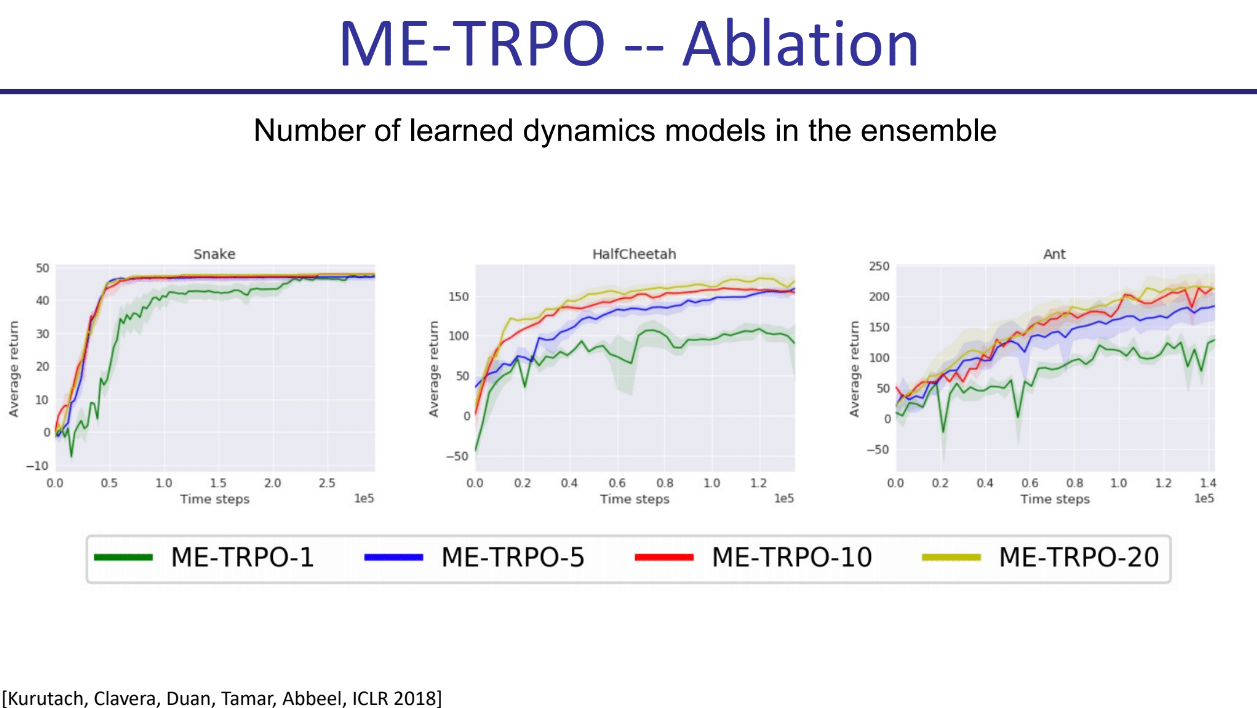
集成中学习的动态模型数量
- 实验比较了使用不同数量模型(1, 5, 10, 20)的ME-TRPO性能。结果显示,在HalfCheetah和Ant环境中,使用更多的模型(特别是5个或10个)可以带来更好的性能和稳定性。
三、Adaptive Model-based RL: Model-based Meta-Policy Optimization (MB-MPO)
解决Model-based RL的渐进性能问题
- 问题: 因为学习到的(集成)模型不完美,导致的策略在模拟中表现很好,但在真实世界中并非最优。
- 尝试的修复方案1: 学习更好的动态模型。事实证明这还不够。
- 尝试的修复方案2: 通过元策略优化(meta-policy optimization)进行模型基强化学习,即MB-MPO。
- 核心思想:
- 学习一个能够代表真实世界通常如何运作的模型集成。
- 学习一个自适应策略,该策略可以快速适应任何一个学习到的模型。
- 这样一个自适应策略也就能快速地适应真实世界的运作方式。
MB-MPO 算法
需要: 内外两层步长
- 初始化策略
,模型 ... 以及数据集 。 - 循环直到策略在真实环境中表现良好:
- 使用适应后的策略
从真实环境中采样轨迹,并添加到D中。 - 使用D训练所有模型。
- 对于所有模型
: - 使用
从模型 中采样虚拟轨迹 。 - 使用轨迹
计算适应后的参数: - 使用适应后的策略
从模型 中采样虚拟轨迹 。
- 使用
- 使用轨迹
更新 :
- 使用适应后的策略
- 返回最优的更新前参数
。
MB-MPO 评估
实验环境: 
与SOTA Model-Free方法的比较:
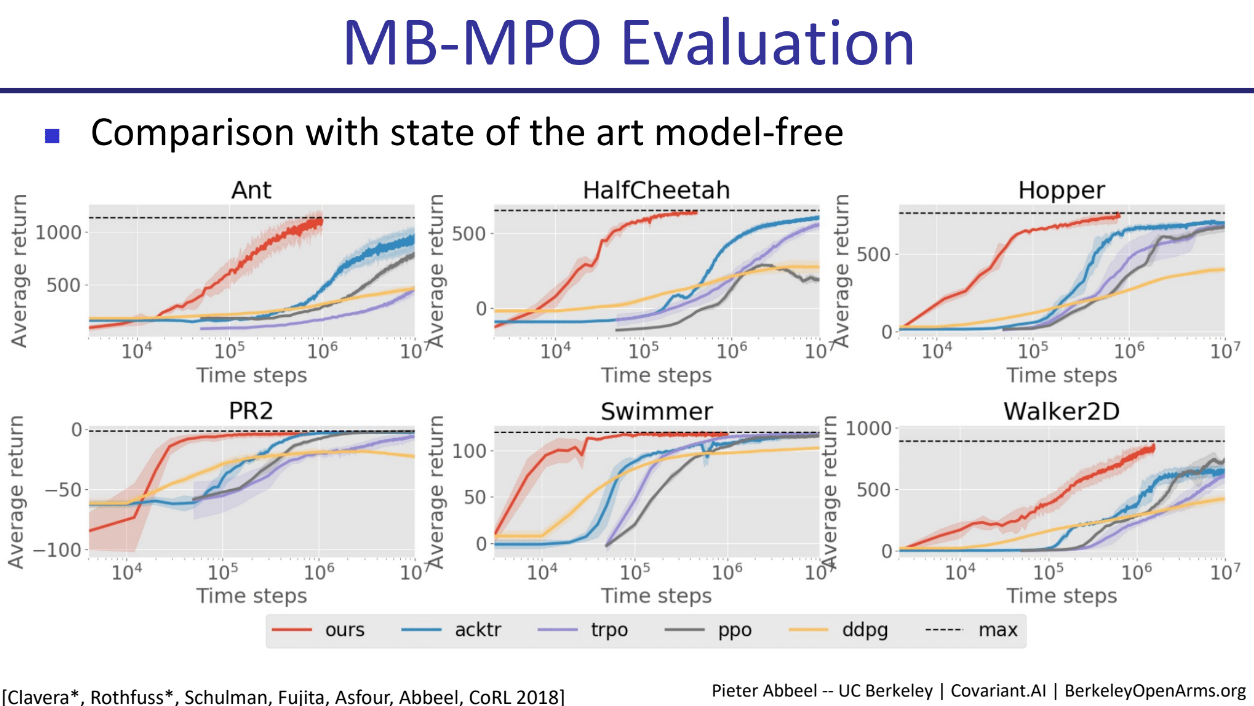
MB-MPO在多个环境中与acktr, trpo, ppo, ddpg等先进的无模型方法进行比较。结果显示MB-MPO(图中ours)在样本效率和渐进性能上都达到了顶尖水平。
与SOTA Model-Based方法的比较:
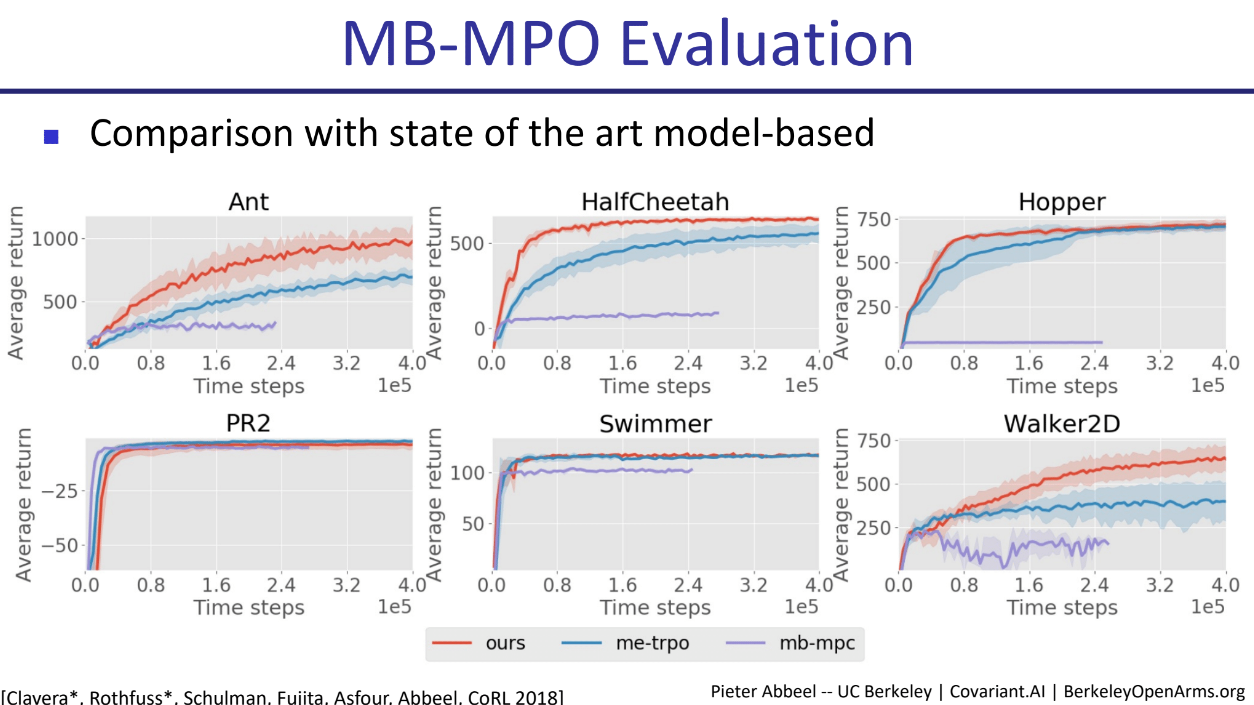
MB-MPO(图中ours)与me-trpo和mb-mpc进行了比较。在Ant, HalfCheetah, Hopper, Walker2D等环境中,MB-MPO在学习速度和最终性能上均表现出明显优势。
- 标题: Model-based RL
- 作者: Felix Christian
- 创建于 : 2025-07-14 00:47:05
- 更新于 : 2025-07-14 01:04:57
- 链接: https://felixchristian.top/2025/07/14/21-DeepRL_lecture6/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。