
DDPG and SAC
一、Deep Deterministic Policy Gradient (DDPG)
基本流程:
Roll-outs
在当前策略下执行 roll-out(执行策略并采样轨迹),加入一些噪声用于探索。Q 函数更新
更新 Q 函数的目标值为:
最小化以下损失函数以更新 Q:
策略更新
通过反向传播 Q 函数来估计策略梯度并更新策略参数:
技术细节:
- 添加噪声促进探索
- 使用 replay buffer 和 target network(从 DQN 中借鉴)以提升稳定性
- 目标值使用 Polyak-averaging 的滞后版本的
和 进行计算
- 添加噪声促进探索
总结:
- 优点:由于是 off-policy,采样效率高
- 缺点:容易不稳定
这也引出了后续改进的算法 —— SAC,它通过在目标中加入策略熵,提升探索能力并减少策略对 Q 函数偏差的过拟合。
二、Soft Actor Critic (SAC)
Soft Policy Iteration:
SAC 的理论基础是 Soft Policy Iteration,包括以下步骤:
Soft policy evaluation(策略评估)
固定策略,应用 soft Bellman backup 直到收敛:
Soft policy improvement(策略改进)
通过信息投影来更新策略:
最小化策略与 soft Q 的 KL 散度重复执行以上两步,直到收敛
对于新的策略,有:
SAC 算法流程:
目标函数:最大化 Q 值与策略熵的组合
重复以下操作:
- 从当前策略
中执行一个动作,与环境交互,并将数据添加到 replay buffer - 使用采样数据来学习 V、Q 和策略
- 对 V 使用 soft Bellman residual 最小化
- 对策略使用最小化 KL 散度的方式进行更新
- 对 V 使用 soft Bellman residual 最小化
- 从当前策略
实验效果
SAC 在多个真实机器人实验中表现出良好效果,如图示:
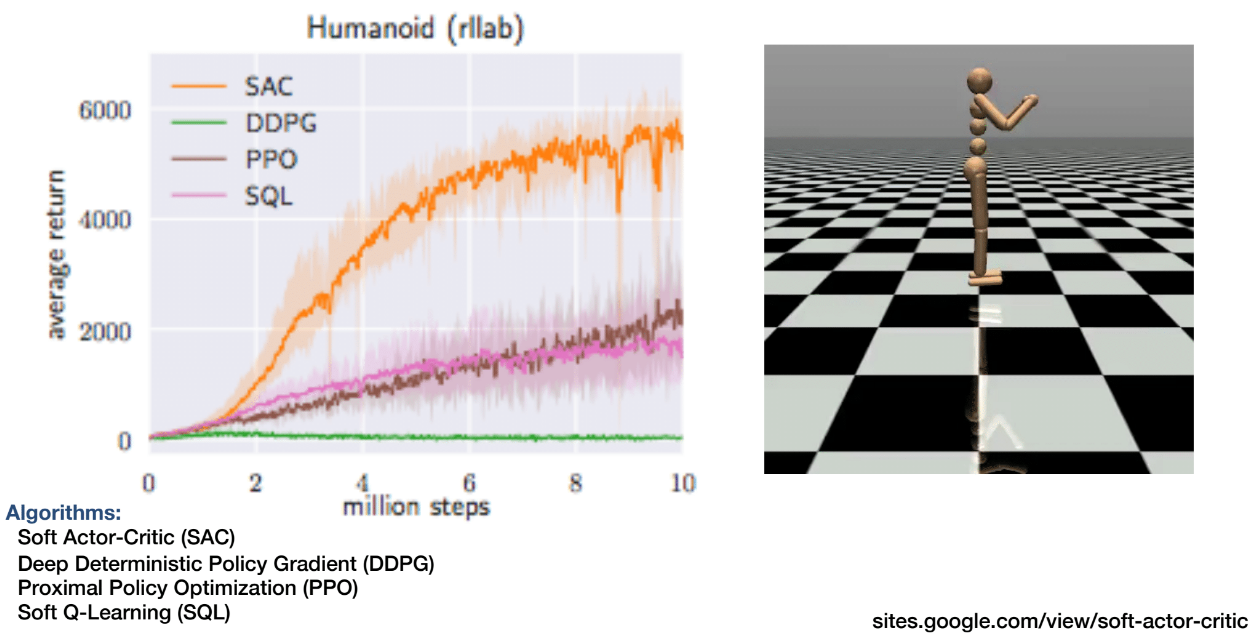
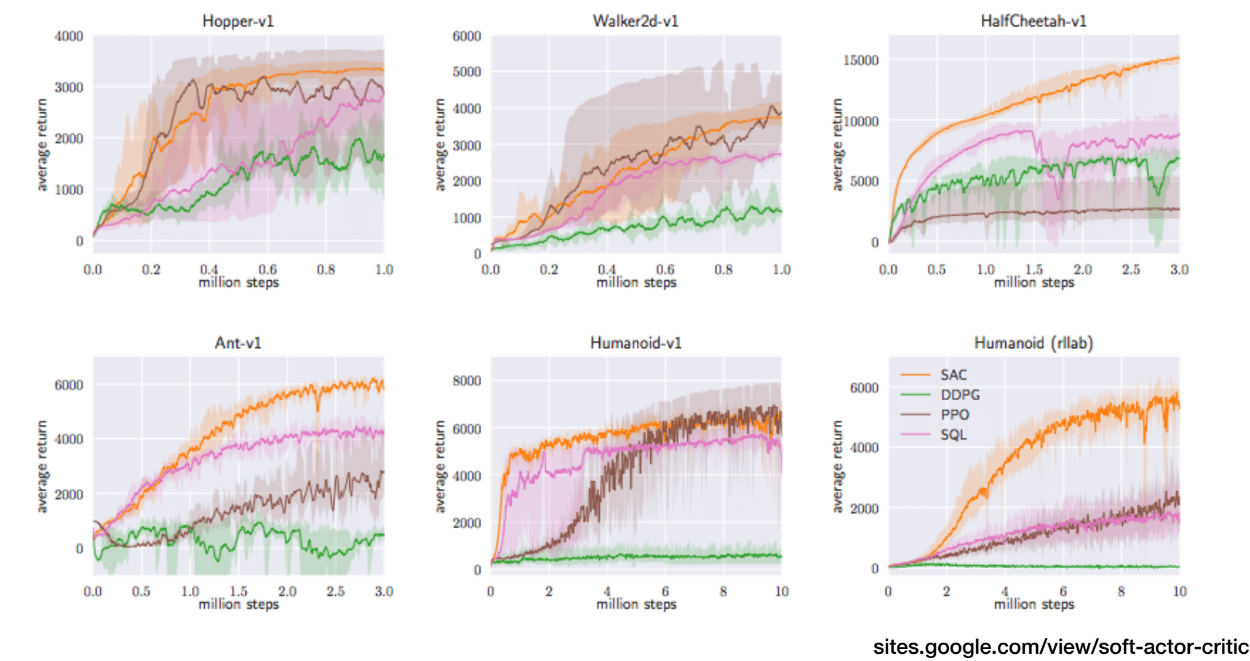
总结
- DDPG:Deterministic 策略 + Off-policy + 高采样效率,但稳定性差
- SAC:Stochastic 策略 + Off-policy + 加入策略熵提升探索性和鲁棒性,是对 DDPG 的改进
- 标题: DDPG and SAC
- 作者: Felix Christian
- 创建于 : 2025-07-14 00:36:05
- 更新于 : 2025-07-14 01:03:51
- 链接: https://felixchristian.top/2025/07/14/20-DeepRL_lecture5/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
评论